PWN从入门到放弃(13)——了解堆
0x00 什么是堆
堆是分配给每个程序的一个内存区域。与堆栈不同,堆内存可以动态分配。这意味着程序可以在需要时从堆中 “申请 “和 “释放 “内存。另外,这个内存是全局的,也就是说,它可以从程序中的任何地方被访问和修改,而不是被分配到指定函数上。这是通过使用 “指针 “来引用动态分配的内存来实现的,与使用堆栈上相比,这又导致了性能上的小幅下降。
0x01 Dynamic Memory
GLibc 采用 ptmalloc2 内存分配器管理堆内存,相比前身 dlmalloc,它增加了对多线程的支持。多线程的好处就不多赘述了。
stdlib.h提供了标准库函数来访问、修改和管理动态内存。
借助stdlib.h我们可以使用malloc和free函数来操作堆内存:
// Dynamically allocate 10 bytes
char *buffer = (char *)malloc(10);
strcpy(buffer, "hello");
printf("%s\n", buffer); // prints "hello"
// Frees/unallocates the dynamic memory allocated earlier
free(buffer);
- malloc:
/*
malloc(size_t n)
Returns a pointer to a newly allocated chunk of at least n
bytes, or null if no space is available. Additionally, on
failure, errno is set to ENOMEM on ANSI C systems.
If n is zero, malloc returns a minimum-sized chunk. (The
minimum size is 16 bytes on most 32bit systems, and 24 or 32
bytes on 64bit systems.) On most systems, size_t is an unsigned
type, so calls with negative arguments are interpreted as
requests for huge amounts of space, which will often fail. The
maximum supported value of n differs across systems, but is in
all cases less than the maximum representable value of a
size_t.
*/
- free:
/*
free(void* p)
Releases the chunk of memory pointed to by p, that had been
previously allocated using malloc or a related routine such as
realloc. It has no effect if p is null. It can have arbitrary
(i.e., bad!) effects if p has already been freed.
Unless disabled (using mallopt), freeing very large spaces will
when possible, automatically trigger operations that give
back unused memory to the system, thus reducing program
footprint.
*/
注意,即使申请 0 字节内存,malloc依然会分配一个最小的 chunk;如果传给free的参数是空指针,free不会做任何事,而如果传入的是一个已经free过的指针,那么后果是不可预期的。这里尤其需要注意的是,与Java等语言不同,C 语言中释放掉分配到的内存的责任在于程序员,并且分配到的内存只应使用_一次_。
这两个函数在更底层上是使用brk()和mmap()这两个系统调用来管理内存的。
0x02 brk & mmap
1)brk
brk()通过增加break location来获取内存,一开始heap段的起点start_brk和heap段的终点brk指向同一个位置。
- ASLR 关闭时,两者指向 data/bss 段的末尾,也就是
end_data - ASLR 开启时,两者指向 data/bss 段的末尾加上一段随机 brk 偏移
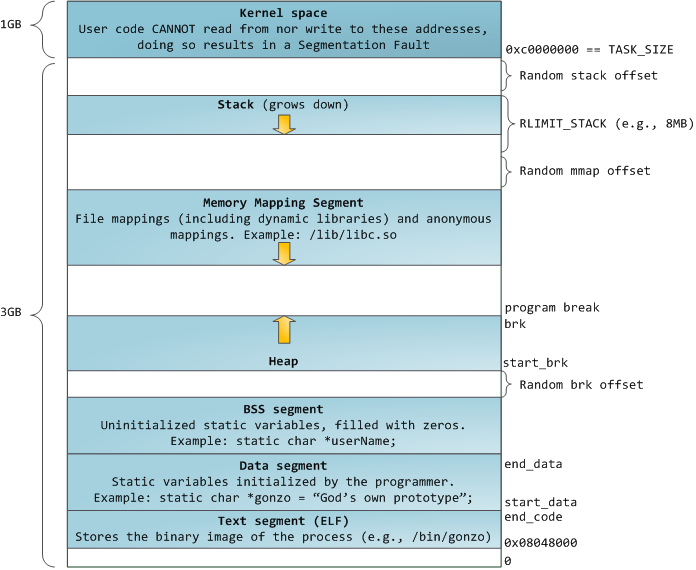
注:注意与sbrk()的区别,后者是 C 语言库函数,malloc源码中的MORECORE就是调用的sbrk()。
2)mmap
用于创建私有的匿名映射段,主要是为了分配一块新的内存,且这块内存只有调用mmap()的进程可以使用,所以称之为私有的。与之进行相反操作的是munmap(),删除一块内存区域上的映射。
0x03 Arena
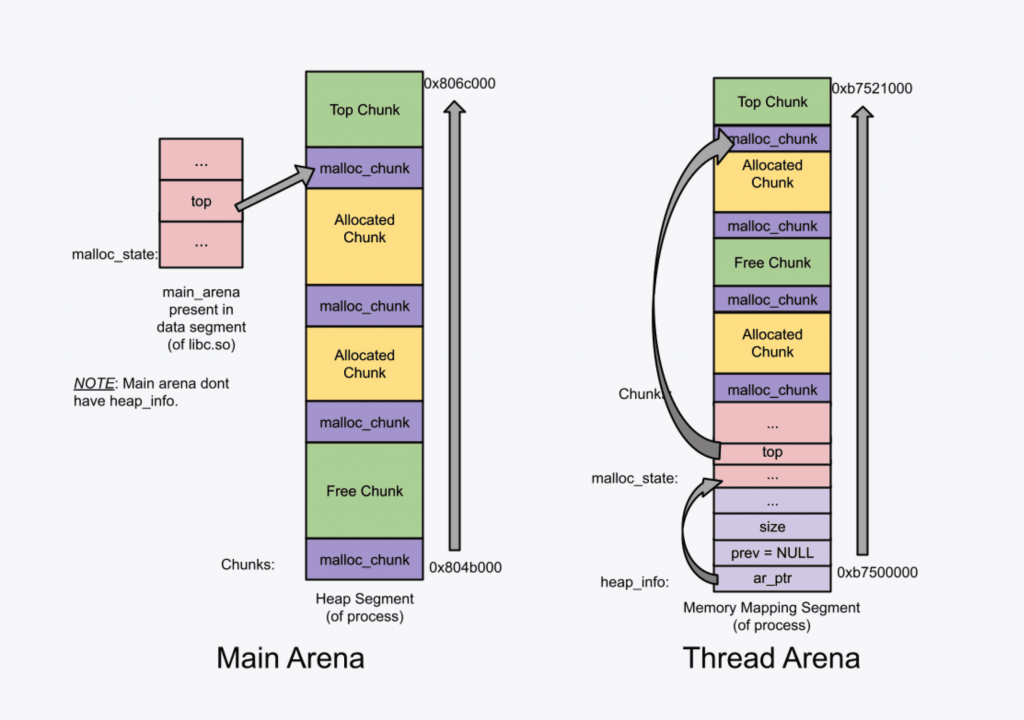
前面提到,ptmalloc2 的一大改进就在于多线程,那么他是如何做到的呢?不难猜到,每个线程必定要维护一些独立的数据结构,并且对这些数据结构的访问是需要加锁的。的确,在 ptmalloc2 中,每个线程拥有自己的freelist,也就是维护空闲内存的一个链表;以及自己的arena(一段连续的堆内存区域)。特别地,主线程的arena叫做main_arena。
注意:只有**main_arena可以访问heap段和mmap映射区域,non_main_arena只能访问mmap**映射区域。
当我们在程序中第一次申请内存时还没有heap段,因此 132KB 的heap段,也就是我们的main_arena,会被创建(通过**brk()**),无论我们申请的内存是多大。对于接下来的内存申请,malloc都会从main_arena中尝试取出一块内存进行分配。如果空间不够,main_arena可以通过brk()扩张;如果空闲空间太多,也可以缩小。
那么对于non_main_arena呢?前面提到它只能访问mmap映射区域,因为在创建时它就是由mmap()创建的——1MB 的内存空间会被映射到进程地址空间,不过实际上只有 132KB 是可读写的,这 132KB 就是该线程的heap结构,或者叫non_main_arena。
而当我们free一小块内存时,内存也不会直接归还给内核,而是给 ptmalloc2 让他去维护,后者会将空闲内存丢入 bin 中,或者说freelist中也可以。如果过了一会我们的程序又要申请内存,那么 ptmalloc2 就会从 bin 中找一块空闲的内存进行分配,找不到的话才会去问内核要内存。
0x04 维护多个堆
前面提到,main_arena只有一个堆,并且可以灵活地放缩;non_main_arena则只能通过mmap()获得一个堆。那么如果non_main_arena里分配的堆内存不够了怎么办?很简单,再mmap()一次,创建一个新的堆。
所以,在non_main_arena里,我们必须考虑如何维护多个堆的问题。这里我们会涉及三个头部:
heap_info:每个堆的头部,main_arena是没有的malloc_state:arena的头部,main_arena的这个部分是全局变量而不属于堆段malloc_chunk:每个 chunk 的头部
具体一点,heap_info完整定义如下:
typedef struct _heap_info
{
mstate ar_ptr; /* Arena for this heap. */
struct _heap_info *prev; /* Previous heap. */
size_t size; /* Current size in bytes. */
size_t mprotect_size; /* Size in bytes that has been mprotected
PROT_READ|PROT_WRITE. */
/* Make sure the following data is properly aligned, particularly
that sizeof (heap_info) + 2 * SIZE_SZ is a multiple of
MALLOC_ALIGNMENT. */
char pad[-6 * SIZE_SZ & MALLOC_ALIGN_MASK];
} heap_info;
而malloc_state的完整定义如下:
struct malloc_state
{
/* Serialize access. */
mutex_t mutex;
/* Flags (formerly in max_fast). */
int flags;
/* Fastbins */
mfastbinptr fastbinsY[NFASTBINS];
/* Base of the topmost chunk -- not otherwise kept in a bin */
mchunkptr top;
/* The remainder from the most recent split of a small request */
mchunkptr last_remainder;
/* Normal bins packed as described above */
mchunkptr bins[NBINS * 2 - 2];
/* Bitmap of bins */
unsigned int binmap[BINMAPSIZE];
/* Linked list */
struct malloc_state *next;
/* Linked list for free arenas. Access to this field is serialized
by free_list_lock in arena.c. */
struct malloc_state *next_free;
/* Number of threads attached to this arena. 0 if the arena is on
the free list. Access to this field is serialized by
free_list_lock in arena.c. */
INTERNAL_SIZE_T attached_threads;
/* Memory allocated from the system in this arena. */
INTERNAL_SIZE_T system_mem;
INTERNAL_SIZE_T max_system_mem;
};
其中INTERNAL_SIZE_T默认和size_t相同:
#ifndef INTERNAL_SIZE_T
#define INTERNAL_SIZE_T size_t
#endif
在后面介绍 chunk 和 bin 的时候,我们会发现其中几个字段的作用,malloc_chunk我们也会在后面看到。
对于arena中只有单个堆的情况
对于non_main_arena中有多个堆的情况:
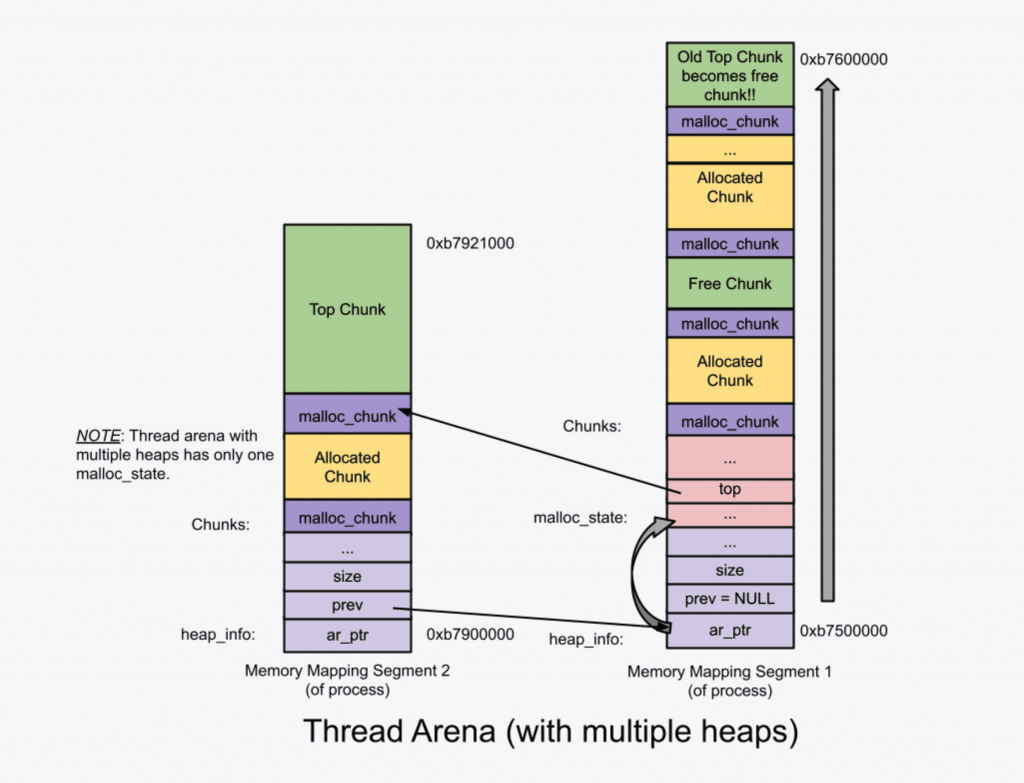
注意到有多个堆的情况下,旧的堆的 Top chunk 会被认为是普通的空闲块。
0x05 Chunk 的结构
通俗地说,一块由分配器分配的内存块叫做一个 chunk,包含了元数据和用户数据。具体一点,chunk 完整定义如下:
struct malloc_chunk {
INTERNAL_SIZE_T mchunk_prev_size; /* Size of previous chunk (if free). */
INTERNAL_SIZE_T mchunk_size; /* Size in bytes, including overhead. */
struct malloc_chunk* fd; /* double links -- used only if free. */
struct malloc_chunk* bk;
/* Only used for large blocks: pointer to next larger size. */
struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */
struct malloc_chunk* bk_nextsize;
};
typedef struct malloc_chunk* mchunkptr;
这里出现的6个字段均为元数据。
一个 chunk 可以是以下几种类型之一:
- 已分配的(Allocated chunk)
- 空闲的(Free chunk)
- Top chunk
- Last Remainder chunk
我们一个一个来看。
1)Allocated chunk

第一个部分(32 位上 4B,64 位上 8B)叫做prev_size,只有在前一个 chunk 空闲时才表示前一个块的大小,否则这里就是无效的,可以被前一个块征用(用于存储用户数据)。
**注:这里的前一个chunk,指内存中相邻的前一个,而不是freelist链表中的前一个。****PREV_INUSE**代表的“前一个chunk”同理。
第二个部分的高位存储当前 chunk 的大小,低 3 位分别表示:
- P:
PREV_INUSE之前的 chunk 已经被分配则为 1 - M:
IS_MMAPED当前 chunk 是mmap()得到的则为 1 - N:
NON_MAIN_ARENA当前 chunk 在non_main_arena里则为 1
对应源码如下:
/* size field is or'ed with PREV_INUSE when previous adjacent chunk in use */
#define PREV_INUSE 0x1
/* extract inuse bit of previous chunk */
#define prev_inuse(p) ((p)->size & PREV_INUSE)
/* size field is or'ed with IS_MMAPPED if the chunk was obtained with mmap() */
#define IS_MMAPPED 0x2
/* check for mmap()'ed chunk */
#define chunk_is_mmapped(p) ((p)->size & IS_MMAPPED)
/* size field is or'ed with NON_MAIN_ARENA if the chunk was obtained
from a non-main arena. This is only set immediately before handing
the chunk to the user, if necessary. */
#define NON_MAIN_ARENA 0x4
/* check for chunk from non-main arena */
#define chunk_non_main_arena(p) ((p)->size & NON_MAIN_ARENA)
你可能会有几个困惑:
fd、bk、fd_nextsize、bk_nextsize这几个字段去哪里了?
对于已分配的 chunk 来说它们没用,所以也被征用了,用来存储用户数据。
- 为什么第二个部分的低 3 位就这么被吞了而不会影响
size?
这是因为malloc会将用户申请的内存大小转化为实际分配的内存,以此来满足(至少)8字节对齐的要求,同时留出额外空间存放 chunk 头部。由于(至少)8字节对齐了,低3位自然就没用了。在获取真正的size时,会忽略低3位:
/*
Bits to mask off when extracting size
Note: IS_MMAPPED is intentionally not masked off from size field in
macros for which mmapped chunks should never be seen. This should
cause helpful core dumps to occur if it is tried by accident by
people extending or adapting this malloc.
*/
#define SIZE_BITS (PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
/* Get size, ignoring use bits */
#define chunksize(p) ((p)->size & ~(SIZE_BITS))
malloc是如何将申请的大小转化为实际分配的大小的呢?
核心在于request2size宏:
/* pad request bytes into a usable size -- internal version */
#define request2size(req) \
(((req) + SIZE_SZ + MALLOC_ALIGN_MASK < MINSIZE) ? \
MINSIZE : \
((req) + SIZE_SZ + MALLOC_ALIGN_MASK) & ~MALLOC_ALIGN_MASK)
其中用到的其它宏定义:
# define MALLOC_ALIGNMENT (2 *SIZE_SZ)
/* The corresponding bit mask value */
#define MALLOC_ALIGN_MASK (MALLOC_ALIGNMENT - 1)
/* The smallest possible chunk */
#define MIN_CHUNK_SIZE (offsetof(struct malloc_chunk, fd_nextsize))
/* The smallest size we can malloc is an aligned minimal chunk */
#define MINSIZE \
(unsigned long)(((MIN_CHUNK_SIZE+MALLOC_ALIGN_MASK) & ~MALLOC_ALIGN_MASK))
- 这里还有一个
mem指针,是做什么用的?
这是调用malloc时返回给用户的指针。实际上,真正的chunk 是从chunk指针开始的。
/* The corresponding word size */
#define SIZE_SZ (sizeof(INTERNAL_SIZE_T))
/* conversion from malloc headers to user pointers, and back */
#define chunk2mem(p) ((void*)((char*)(p) + 2*SIZE_SZ))
#define mem2chunk(mem) ((mchunkptr)((char*)(mem) - 2*SIZE_SZ))
- 用户申请的内存大小就是用户数据可用的内存大小吗?
不一定,原因还是字节对齐问题。要获得可用内存大小,可以用malloc_usable_size()获得,其核心函数是:
static size_t
musable (void *mem)
{
mchunkptr p;
if (mem != 0)
{
p = mem2chunk (mem);
if (__builtin_expect (using_malloc_checking == 1, 0))
return malloc_check_get_size (p);
if (chunk_is_mmapped (p))
return chunksize (p) - 2 * SIZE_SZ;
else if (inuse (p))
return chunksize (p) - SIZE_SZ;
}
return 0;
}
2)Free chunk
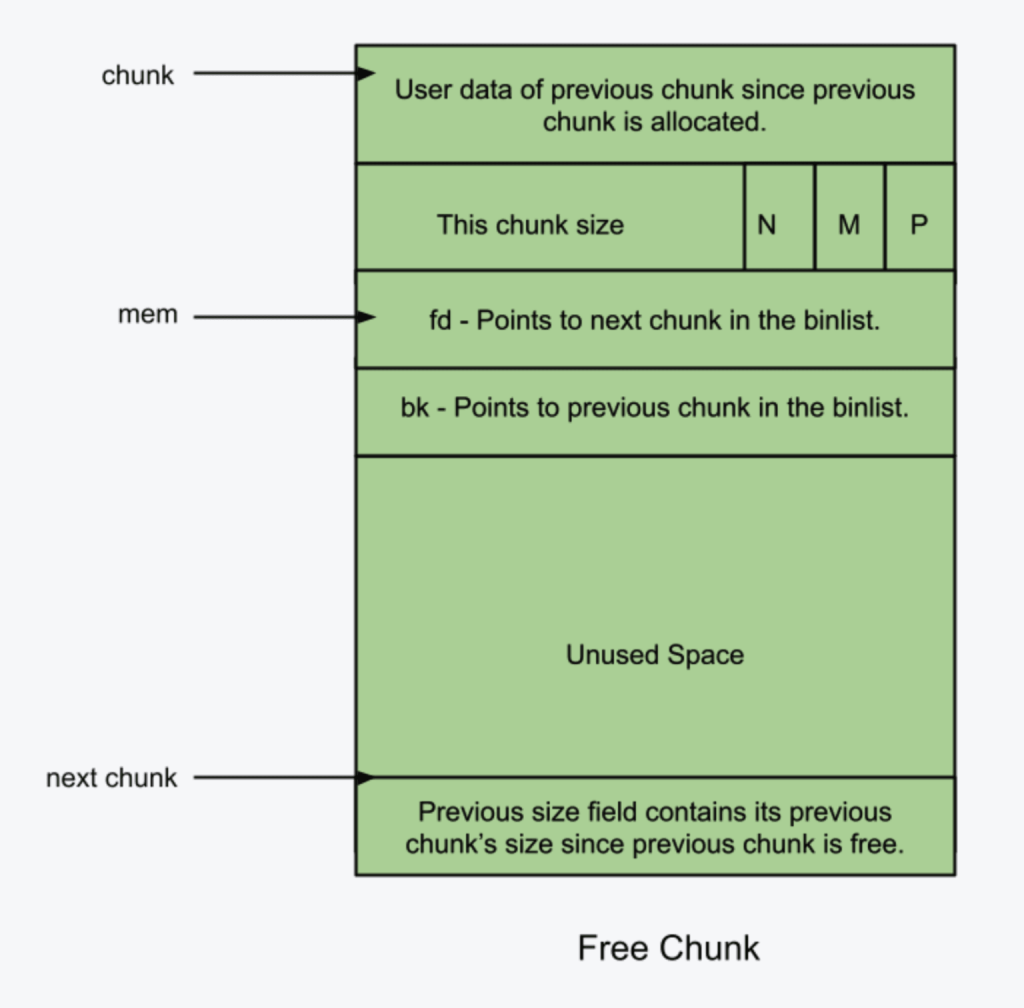
首先,prev_size必定存储上一个块的用户数据,因为 Free chunk 的上一个块必定是 Allocated chunk,否则会发生合并。
接着,多出来的fd指向同一个 bin 中的前一个 Free chunk,bk指向同一个 bin 中的后一个 Free chunk。
3)Top chunk
一个arena顶部的 chunk 叫做 Top chunk,它不属于任何 bin。当所有 bin 中都没有空闲的可用 chunk 时,我们切割 Top chunk 来满足用户的内存申请。假设 Top chunk 当前大小为 N 字节,用户申请了 K 字节的内存,那么 Top chunk 将被切割为:
- 一个 K 字节的 chunk,分配给用户
- 一个 N-K 字节的 chunk,称为 Last Remainder chunk
后者成为新的 Top chunk。如果连 Top chunk 都不够用了,那么:
- 在
main_arena中,用brk()扩张 Top chunk - 在
non_main_arena中,用mmap()分配新的堆
注:Top chunk 的 PREV_INUSE 位总是 1
4)Last Remainder chunk
当需要分配一个比较小的 K 字节的 chunk 但是 small bins 中找不到满足要求的,且 Last Remainder chunk 的大小 N 能满足要求,那么 Last Remainder chunk 将被切割为:
- 一个 K 字节的 chunk,分配给用户
- 一个 N-K 字节的 chunk,成为新的 Last Remainder chunk
它的存在使得连续的小空间内存申请,分配到的内存都是相邻的,从而达到了更好的局部性。
0x06 Bin 的结构
bin 是实现了空闲链表的数据结构,用来存储空闲 chunk,可分为:
- 10 个 fast bins,存储在
fastbinsY中 - 1 个 unsorted bin,存储在
bin[1] - 62 个 small bins,存储在
bin[2]至bin[63] - 63 个 large bins,存储在
bin[64]至bin[126]
还是一个一个来看。
1)fast bins
非常像高速缓存 cache,主要用于提高小内存分配效率。相邻空闲 chunk 不会被合并,这会导致外部碎片增多但是free效率提升。注意 fast bins 是 10 个 LIFO 的单链表。最后三个链表保留未使用。
chunk大小(含chunk头部):0x10-0x40(64位0x20-0x80)B,相邻bin存放的大小相差0x8(0x10)B。
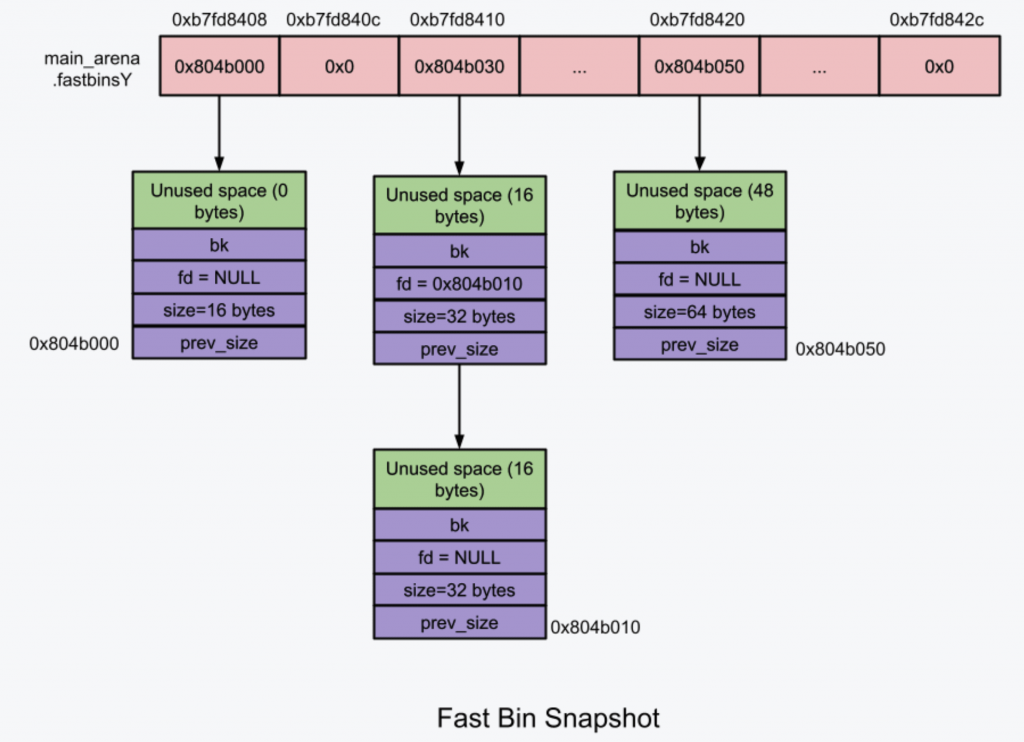
注:加入 fast bins 的 chunk,它的**IN_USE位(准确地说,是下一个 chunk 的PREV_INUSE**位)依然是 1。这就是为什么相邻的“空闲”chunk 不会被合并,因为它们根本不会被认为是空闲的。
关于fastbin最大大小,参见宏DEFAULT_MXFAST:
#ifndef DEFAULT_MXFAST
#define DEFAULT_MXFAST (64 * SIZE_SZ / 4)
#endif
在初始化时,这个值会被赋值给全局变量global_max_fast。
申请fast chunk时遵循first fit原则。释放一个fast chunk时,首先检查它的大小以及对应fastbin此时的第一个chunk old的大小是否合法,随后它会被插入到对应fastbin的链表头,此时其fd指向old。
2)unsorted bin
非常像缓冲区 buffer,大小超过 fast bins 阈值的 chunk 被释放时会加入到这里,这使得 ptmalloc2 可以复用最近释放的 chunk,从而提升效率。
unsorted bin 是一个双向循环链表,chunk 大小:大于global_max_fast。
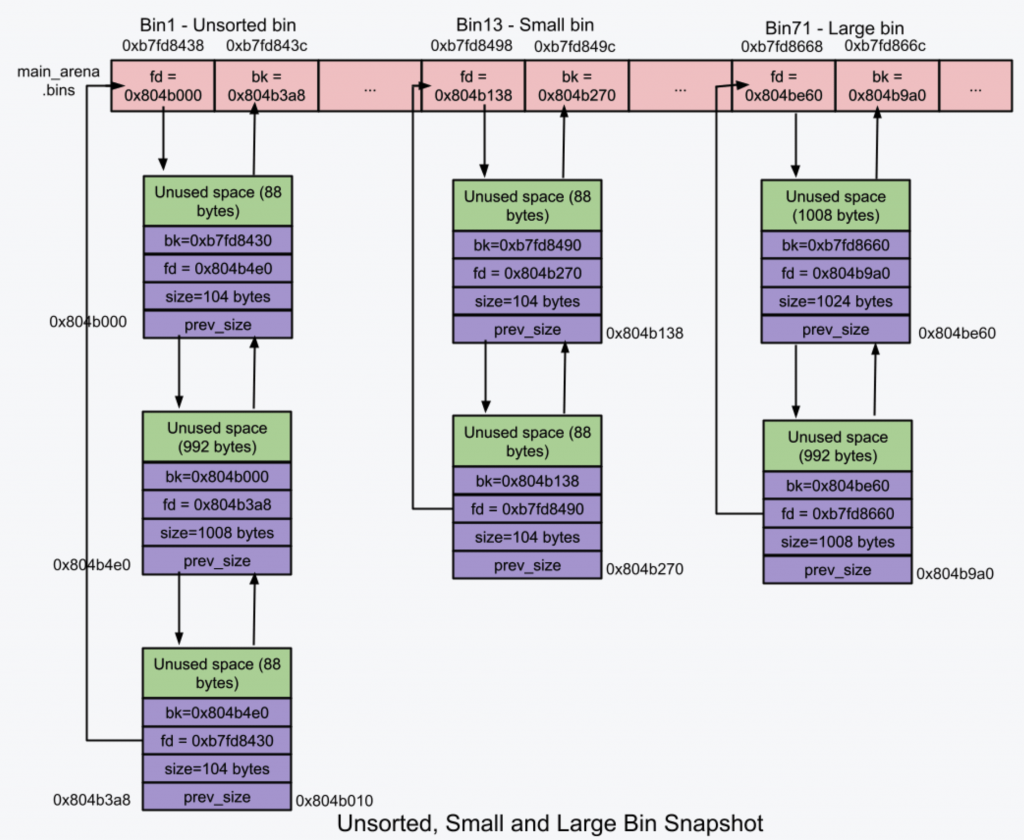
当程序申请大于global_max_fast内存时,分配器遍历unsorted bin,每次取最后的一个unsorted chunk。
- 如果unsorted chunk满足以下四个条件,它就会被切割为一块满足申请大小的chunk和另一块剩下的chunk,前者返回给程序,后者重新回到unsorted bin。
- 申请大小属于small bin范围
- unosrted bin中只有该chunk
- 这个chunk同样也是last remainder chunk
- 切割之后的大小依然可以作为一个chunk
- 否则,从unsorted bin中删除unsorted chunk。
- 若unsorted chunk恰好和申请大小相同,则直接返回这个chunk
- 若unsorted chunk属于small bin范围,插入到相应small bin
- 若unsorted chunk属于large bin范围,则跳转到3。
- 此时unsorted chunk属于large bin范围。
- 若对应large bin为空,直接插入unsorted chunk,其
fd_nextsize与bk_nextsize指向自身。 - 否则,跳转到4。
- 若对应large bin为空,直接插入unsorted chunk,其
- 到这一步,我们需按大小降序插入对应large bin。
- 若对应large bin最后一个chunk大于unsorted chunk,则插入到最后
- 否则,从对应large bin第一个chunk开始,沿
fd_nextsize(即变小)方向遍历,直到找到一个chunkfwd,其大小小于等于unsorted chunk的大小- 若
fwd大小等于unsorted chunk大小,则插入到fwd后面 - 否则,插入到
fwd前面
- 若
直到找到满足要求的unsorted chunk,或无法找到,去top chunk切割为止。
3)small bins
小于 0x200(0x400)B 的 chunk 叫做 small chunk,而 small bins 可以存放的就是这些 small chunks。chunk 大小同样是从 16B 开始每次+8B。
small bins 是 62 个双向循环链表,并且是 FIFO 的,这点和 fast bins 相反。同样相反的是相邻的空闲 chunk 会被合并。
chunk大小:0x10-0x1f0B(0x20-0x3f0),相邻bin存放的大小相差0x8(0x10)B。
释放非fast chunk时,按以下步骤执行:
- 若前一个相邻chunk空闲,则合并,触发对前一个相邻chunk的
unlink操作 - 若下一个相邻chunk是top chunk,则合并并结束;否则继续执行3
- 若下一个相邻chunk空闲,则合并,触发对下一个相邻chunk的
unlink操作;否则,设置下一个相邻chunk的PREV_INUSE为0 - 将现在的chunk插入unsorted bin。
- 若
size超过了FASTBIN_CONSOLIDATION_THRESHOLD,则尽可能地合并fastbin中的chunk,放入unsorted bin。若top chunk大小超过了mp_.trim_threshold,则归还部分内存给OS。
#ifndef DEFAULT_TRIM_THRESHOLD
#define DEFAULT_TRIM_THRESHOLD (128 * 1024)
#endif
#define FASTBIN_CONSOLIDATION_THRESHOLD (65536UL)
4)large bins
大于等于 0x200(0x400)B 的 chunk 叫做 large chunk,而 large bins 可以存放的就是这些 large chunks。
large bins 是 63 个双向循环链表,插入和删除可以发生在任意位置,相邻空闲 chunk 也会被合并。chunk 大小就比较复杂了:
- 前 32 个 bins:从 0x200B 开始每次+0x40B
- 接下来的 16 个 bins:每次+0x200B
- 接下来的 8 个 bins:每次+0x1000B
- 接下来的 4 个 bins:每次+0x8000B
- 接下来的 2 个 bins:每次+0x40000B
- 最后的 1 个 bin:只有一个 chunk,大小和 large bins 剩余的大小相同
注:同一个 bin 中的 chunks 不是相同大小的,按大小降序排列。这和上面的几种 bins 都不一样。而在取出chunk时,也遵循**best fit**原则,取出满足大小的最小chunk。
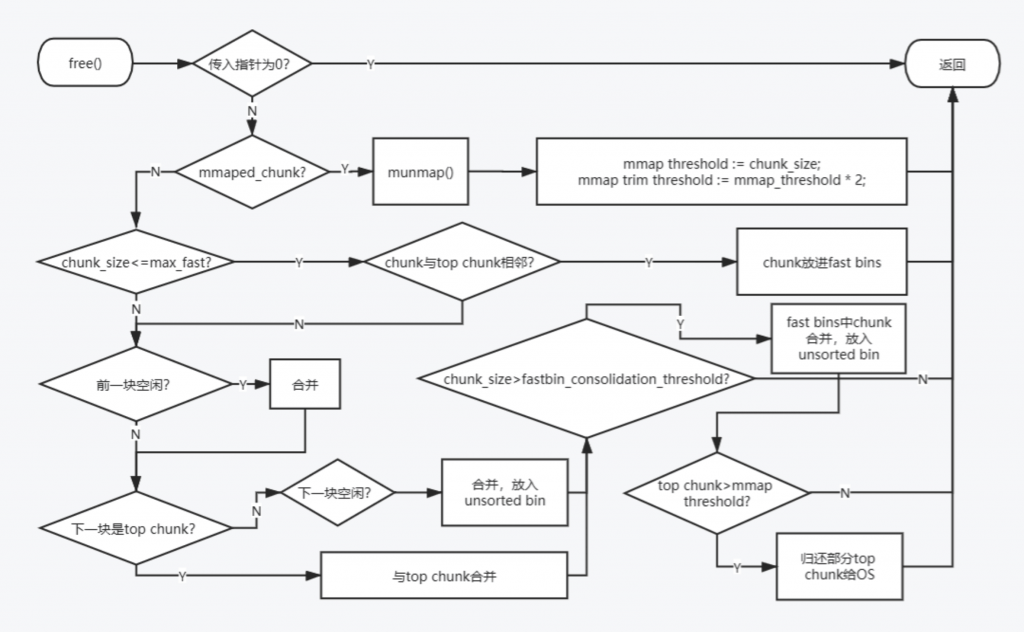
0x07 内存分配流程

0x08 内存释放流程